Praanscribe is an open-source Pyhton application developed with the aim of automizing the process of segmenting parts of speech as much as possible using Praat.
Purpose, theoretical & conceptual background
Automatic Speech Recognition & Segmentation
Automatic Speech Recognition (ASR) and segmentation systems and technologies play a central role in contemporary phonetic and phonological research. ASR systems convert spoken language into textual or symbolic representations, facilitating linguistic analysis at various levels (Jurafsky & Martin, 2023). Temporal segmentation — identifying word, syllable, or sentence boundaries — is crucial in aligning acoustic signals with linguistic units for both qualitative and quantitative analyses.
Praat (Boersma & Weenink, 2001), a widely adopted tool in phonetic research, offers a robust framework for acoustic analysis and manual annotation. Its annotation system, based on TextGrid objects, allows researchers to align linguistic information with audio data at multiple tiers (e.g., phonemes, words, sentences), making it ideal for controlled linguistic experiments and large-scale corpus studies. However, manual annotation remains time-consuming and prone to inconsistency, especially in large datasets.This challenge underscores the need for tools that integrate ASR with platforms like Praat to automate and standardize transcription and segmentation. Praanscribe addresses this need by generating timestamped, sentence-aligned transcriptions and .TextGrid files from audio inputs. This facilitates efficient annotation workflows and enhances reproducibility in phonetic and phonological analyses.
Architecture of Praanscribe
Praanscribe was written in Pyhton programming language and runs OpenAI’s Whisper API locally to transcribe any input provided by the user in a sound file format. It has options for using five models from the smallest to the largest and supports 99 languages. Whisper’s tagging system is used for determining the starting and ending of words and sentences which are then used to convert the transcribed data into a TextGrid file, which can be used in Praat without any altercation needed. The latest version of Praanscribe automizes the word and sentence level transcriptions.
Praat uses the ‘TextGrid’ file format to integrate annotations into audio files. Manual transcription is frequently used during this process. The application’s goal is to automate this procedure by transcribing the utterances from audio files and generating TextGrid files that match the original audio’s length.
In the latest version of Praanscribe, the application can; transcribe sentence-level and word-level utterances, align them in a textgrid file according to their starting and ending points, and do grepheme-to-phoneme conversion. Some limitations to this framework is that it uses a corpus-based AI, and it most likely will not accurately transcribe pseudowords and will prioritize words with higher usage frequency. Also, the G2P method is found to be useful for standard variation, but lacks in capturing variational differences.
Praanscribe was used for annotating speech data in the TÜBİTAK project 223K318,
Uzun, İ.P. (2025). Türkçede Bileşik Sözcüklerin Sözlü Dilde Üretim Süreçlerine İlişkin Akustik Sesbilgisel Görünümler, Tübitak 1002-A Hızlı Destek Modülü.
Logic
Praanscribe uses OpenAI’s Whisper AI to transcribe and tag word-level and sentence-level utterances. It then fits them into a .TextGrid file according to the needs of the end user.
Usage
Run Praanscribe script in a Python environment
Locate and provide the audio data → Lossless file formats such as .flac and .wav along with lossy .mp3 and .aac are supported.
Choose the model to be used → The Whisper AI comes with 6 models, Praanscribe supports 5: tiny, base, small, medium, and large. The larger the model, the more accurate it is and the more time and processing power it takes to run it locally.
Choose the tiers to be created → The default is “phones”, “words-phono”, “words”, “phono”, and “ortho”. The end user may edit these parameters accoring to specific applications.
The TextGrid will be saved to the same location as the audio file! ⭐️
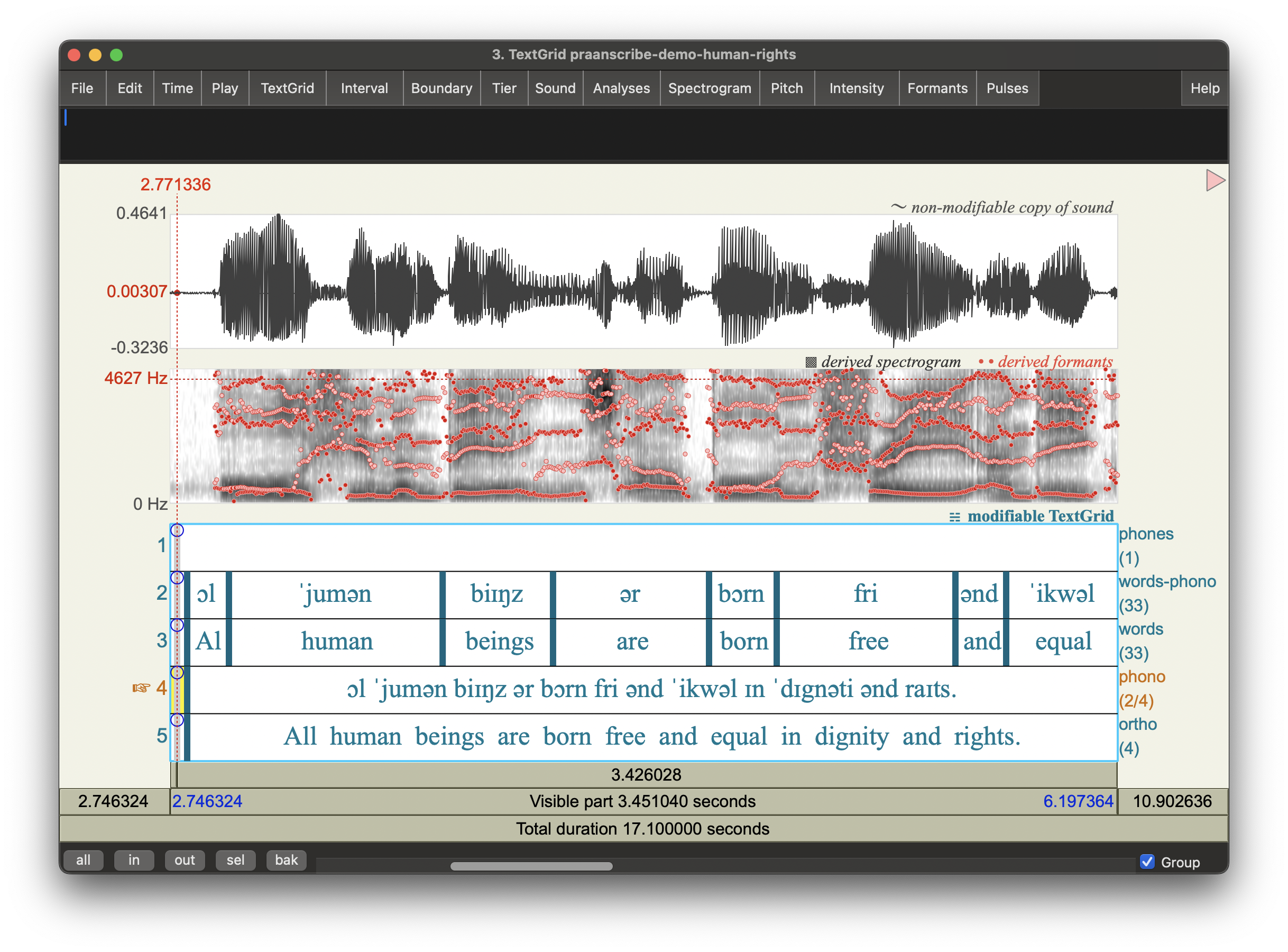
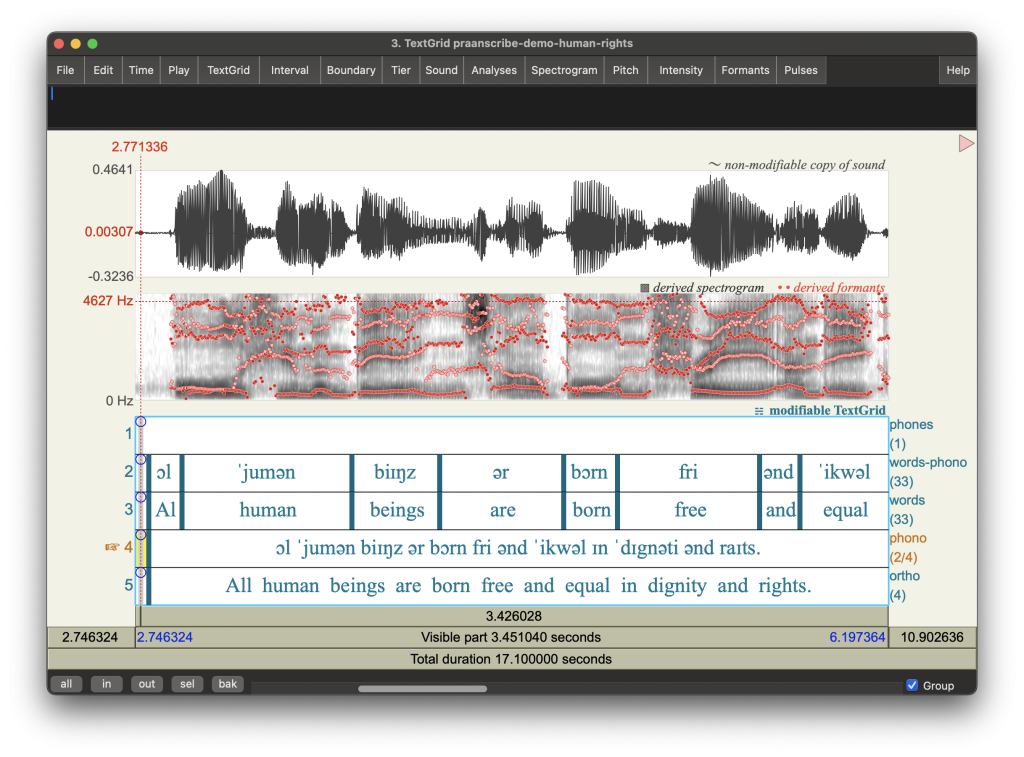
Example Output
Data: U.N. Universal Declaration of Human Rights – LibriVox Library, Public Domain
https://www.youtube.com/watch?v=bbRY3aZLTy0
Projects That Use Praanscribe:
This section is dedicated to projects that have used or are currently using Praanscribe for their research and have chosen to be mentioned on this website. I am honored to contribute in even a small way to their work and am grateful for the opportunity to support their research!
Kaya, A. Ç. (2024). Ölçünlü Türkçenin ünlü formant frekansları., Tübitak 2209-A.
Uzun, İ.P. (2025). Türkçede Bileşik Sözcüklerin Sözlü Dilde Üretim Süreçlerine İlişkin Akustik Sesbilgisel Görünümler, Tübitak 1002-A Hızlı Destek Modülü.
References
Boersma, P. & Weenink, D. (2025). Praat: doing phonetics by computer [Computer program]. Version 6.4.27, retrieved 27 January 2025 from http://www.praat.org/
Goldman, J.-P. (2011) Easyalign: an automatic phonetic alignment tool under praat. Proc.
Interspeech 2011, 3233-3236, doi: 10.21437/Interspeech.2011-815
Van Rossum, G., & Drake, Jr. F. L. (1995). Python reference manual. Centrum voor Wiskunde en Informatica Amsterdam.
Leave a Reply